
My tryst with implementing Role Based Access Control (RBAC) in a web application
At Locus.sh, where I previously worked, people swear by the need of a great RBAC system in place. When I started to work at Catapult & faced with an access control problem, I jumped at the opportunity

Problem Background
My first exposure to the problem of Role Based Access Control was when I worked at Locus.sh . It started with the nifty remote assignment for backend roles - which was to design a minimalistic version of the same. I also remember seeing it as one of the major roadmap item which, for the lack of available bandwidth & in face of prioritizing other roadmap items, was constantly pushed for the subsequent quarters.
It took me a while to realize the ‘why’ behind the problem. The product problem is - some set of people (role), should be able to do certain things like read / write / delete (action type) on certain database entry, file (resource). So it is a mapping of role - resource - action type. You can define these entities as per your logic. A very simplistic version of it is row level security that most modern databases have started to offer, where the data that you have created, only you can modify. Nobody else can.
So what is the big deal about the problem ? The logic can be easily written as a set of rules in your backend system. There are multiple subtle challenges here
Role resolution is resource dependent - The role is now dependent on the resource. For eg, an entry created by me in the database, my role can resolve as owner. But it should NOT resolve as owner for an entry created by someone else
RBAC as querying engine is ideal but hard to implement - Take an example from above. Ideally, I should be able to get all database entries where I am the owner. One obvious way to implement it is - fetch all DB entries & then do role resolution for each entry & filter out the ones I am NOT an owner of. This is fairly expensive. This is what I had in mind when I suggested the solution at Locus & I remember Geet (the CTO) mentioning to me this exact situation & how he would expect the system to work.
Mixing CRUD & RBAC in the same backend code could be fatal - Lets take the above example. We implemented approach 2 anyway - we pick all entries & then we filter. Now, the role resolution ended up having a bug & it started resolving role for all entries as owner for everyone. Now you are serving all entries to everyone. This is one of the most common ways multi tenant systems gets broken on production. But traditionally, for a very long time, most folks have worked with this approach, because, lack of option maybe.
The NFT privacy problem at Catapult
When I joined Catapult Labs in Oct 2022, I started to work on Catapult User Dashboard. One of the things Catapult let DAO users do, is to let them create their web3 profile & then find other web3 users who are registered on Catapult. The users can import NFTs linked to their wallet & we wanted the users to be able to control privacy as not all NFTs are ‘show worthy’ .
At that point, most of the Catapult code was written on the ‘frontend’ with Firebase (actually Firestore) as the DB. We were using Firebase auth so the user is identified at the start & all DB operations were done as the user (& not as a global user as to how it is being traditionally done with the DBs). This is where I identified the ingenuity of Firebase. Letting operations done as the user, eliminates the need of a CRUD backend. We used Firestore & there is something called Firestore Security Rules which lets you implement row level security & more complex Role Based Access control rules. But at this point, we were unaware of the power of this feature that Firebase provides.
By design, most user specific things like editing his profile details etc happened as the user & was done directly from the frontend. There were backend functions (I actually did not know that Firebase has this serverless function support which is pretty nifty) to do things that are user agnostic (or basically actions that need to be done before user is identified) . One of such operation was to identify user (lets say from email or some 3rd party auth like Discord) & create/return firebase auth token to the frontend which is what the frontend uses to do direct DB operations. So far so good.
Implementing NFT privacy was a challenge as we wanted to do it from frontend. But then, as mentioned in point 2, fetching all NFTs & then filtering the ones out which are marked private, defeats the purpose. The first solution proposed was to move the NFT fetching & filtering to the backend (a Firebase function) so that we are NOT getting all the NFTs to frontend, from where, it was fairly easy to snoop for any reasonable frontend developer. I knew, this is a piecemeal approach & I suggested that we do the implementation in frontend & I decided to spend time, figuring out how we can tell firebase NOT to serve these NFTs which user has marked private. This was inspired by point 3 - decoupling the fetch & gatekeeping logic - so that if the code had a bug & failed to owner the privacy field, the gatekeeping logic stops the request from getting fulfilled.
Enter Firebase
I wanted to write it like Enter Sandman from Metallica & I wished the initial guitar riff played at the background but guess I would just satisfy myself with this attribution here
I remember spending an entire week reading up Firebase & its features, sometime in Oct. Most developers like me, have certain disdain to NoSQL Databases like Firebase. They have eventual consistencies ( I still remember my teams struggling with DynamoDB migration from Oracle in Amazon ), you can NOT do table joins, you can NOT write transactions & indexing probably would not work as fast as in SQL DBs.
The more I spent time reading Firebase, except for table join, Firebase could support everything else. Maybe other NoSQL DBs have the same advantage but well, what follows, made me a real fan of Firebase.
Firebase has 2 DB types - Firestore & Realtime DB. We had chosen Firestore & to be honest, till this date, I am not sure which one to choose. My approach to solving a problem, is to trust the decisions of the past & then see what best we can do, before I hit a dead-end & then take a step back & reconsider the last decision ( consider it like Depth First Search vs Breadth First Search .. if you are a techie, you would know which one I talked about :-] ) . So I chose to believe Firestore is the right choice & moved on from there.
Firestore data structure is typically a hierarchical data of collections & documents. We had stored all the user data in a users-main collection & each document in the collection has the uid as the document id. The document also contained uid as one of the document field
users-main (collection)
0EbXqhcPOhTmY2efwwS5KDqEsz63 (document id)
{
uid: "0EbXqhcPOhTmY2efwwS5KDqEsz63"
name: "Ashish"
NFTs: {
random-nft-1: {
privacy: "Private"
image_url: "https://some-cdn-path/img.png"
}
awesome-nft-2: {
privacy: "Public"
image_url: "https://some-cdn-path/img.png"
}
}
}
In the above example, I have put a sample user document indicating the stored fields. The user could update the privacy field from the UI & we had the feature built already.
The unfolding of Firestore Security Rules quirks
Firestore supported Security Rules which I mentioned before. All I wanted is to write a rule like
If (request from owner)
return all NFTs
else
return NFTs with field marked PublicI remember going back to Greg (CTO of Catapult) & telling Firebase wont gonna work for our usecase. The issue was - Firestore security rules can help gate entire document not a sub-part of the document. At this moment, I remember, Greg said something like - ya we should probably just move our logic to backend we can do all the filtering. I am not sure if it was my hurt ego or never-say-never spirit, but I went back to do some more research.
I figured the solution. It was to move all NFT related data into sub-collection. Since Firestore security rules can gate the entire document, the document under sub-collection will qualify.
We now needed to decide between the two designs
One fields sub-collection with type
users-main (collection)
0EbXqhcPOhTmY2efwwS5KDqEsz63 (document id)
{
uid: "0EbXqhcPOhTmY2efwwS5KDqEsz63"
fields (sub-collection)
name (doc 1)
{
type: "profile-field-or-some-specific-type"
value: "Ashish"
privacy: "Public"
}
random-nft-1 (doc 2)
{
type: "NFT"
privacy: "Private"
image_url: "https://some-cdn-path/img.png"
}
}
Custom sub-collections
users-main (collection)
0EbXqhcPOhTmY2efwwS5KDqEsz63 (document id)
{
uid: "0EbXqhcPOhTmY2efwwS5KDqEsz63"
profile-fields (sub-collection 1)
name (doc 1)
{
value: "Ashish"
privacy: "Public"
}
email (doc 2)
{
value: "jamesbond@007.com"
privacy: "Private"
}
NFTs (sub-collection 2)
random-nft-1 (doc 1)
{
privacy: "Private"
image_url: "https://some-cdn-path/img.png"
}
}We chose the 2nd approach, primarily because it still gave us some structure & when a new developer would review the database, the database fields would make much more sense.
While it was not evident earlier, but the breaking user data into sub-collection also made sense from fetch time perspective. Firebase docs talk about slow loading time due to documents being extremely large in size. The sub-collections are NOT fetched by default & they need to be recursively fetched. It has both pros & cons. Your fetches are going to be faster & you can effectively gate them at DB level. But then you end up paying more money because apparently every Firebase fetch cost money. At Catapult, this hasn’t become an issue yet so I did not research on the cost angle.
How did the Security Rule looked like
So I dont intend this to be ‘step by step guide’ for implementing Firebase security rules as there are enough resources on the web for the same. But for completeness sake & if you are new to Firebase/Firestore, I would quickly show how the final rule looked like (you need to create a firestore.rules file & add below to it)
rules_version = '2';
service cloud.firestore {
match /databases/{database}/documents {
match /users-main/{userId}/NFTs/{nft} {
allow read: if request.auth.uid == userId || resource.data.privacy == "Public";
allow write: if request.auth.uid == userId;
}
}
}With the paths should be evident to developers, the part between ‘{..}’ matches value in the path & stores it in a variable that you can use in the rule (check how userId variable is used). `request` & `resource` objects have a lot of information that you can potentially use to write your rules. But I will let you refer the Firestore docs if you get to implement it :).
It is worthwhile to note, how Firestore Security Rules address all the 3 points I mentioned at the start of the post
Role resolution is resource dependent - Firebase totally got away from the term role. The resource are represented by the path, the action type is after ‘allow’ keyword. The meatier part is the logic where Firebase provides you auth request data & resource data that you are trying to access.
RBAC as querying engine - Firebase takes a very interesting approach here. So for a query like - get all NFTs of user x - Firebase will internally check if the requesting user is the owner & will fail otherwise. So it is all or none. Firebase will NOT take the middle approach of filtering & providing the data to you. You can read more about it here on Firebase docs and on this Medium article . At this moment, I am not sure if there is a performance penalty because of this but my guess is, this is done to ensure no performance penalty.
Decoupling CRUD & RBAC logic - so by delegating all gate keeping to Firestore rules, the segregation is already created. Having said that, as mentioned in point 2, you need to be aware of what gate keeping allows/disallows else you would see permission denied errors.
The lesser known ‘secrets’ that helped me
I relied a lot on the Firebase videos on the Firebase docs to get to know the Security rules. They mentioned about some kind of Rules Playground but somehow I never used them while developing.
Writing unit tests
For testing, I relied on unit testing using rules-unit-testing package. This particular package had advantage of letting me create a mock user object so that I can try accessing a resource for both positive (I being owner of the resource) & negative scenario. The test setup took a bit of time ( I remember spending at least 2 days ) but I believed that was a time well spent because it setup the right foundation. Providing first version of test if it saves you time as finding the exact test code was hard.
The below code is the first iteration when I created rules that only owner can create/update his own data & other users (including unauthenticated users) can just read data. The test code is here & the setup code for test is here . I wanted to insert them at github gist but substack behaved a little weirdly.
For the tests, I could not get the firestore rules to be loaded from the file in the tests so everytime I updated the rules, I needed to restart emulator with the rules loaded before running tests.
Also, I faced a weird issue that document reference was cached. So when I updated a field in a document & when I try to get the document reference as a different user, it returned the document reference as the previous user.
Using Firestore Requests tab to see if requests are denied
The unit tests helped me being fairly certain about how the rules are behaving. But to audit them when the actual app ran, the Firestore Emulator Suite helped figuring out if any of the situation went out of hand.
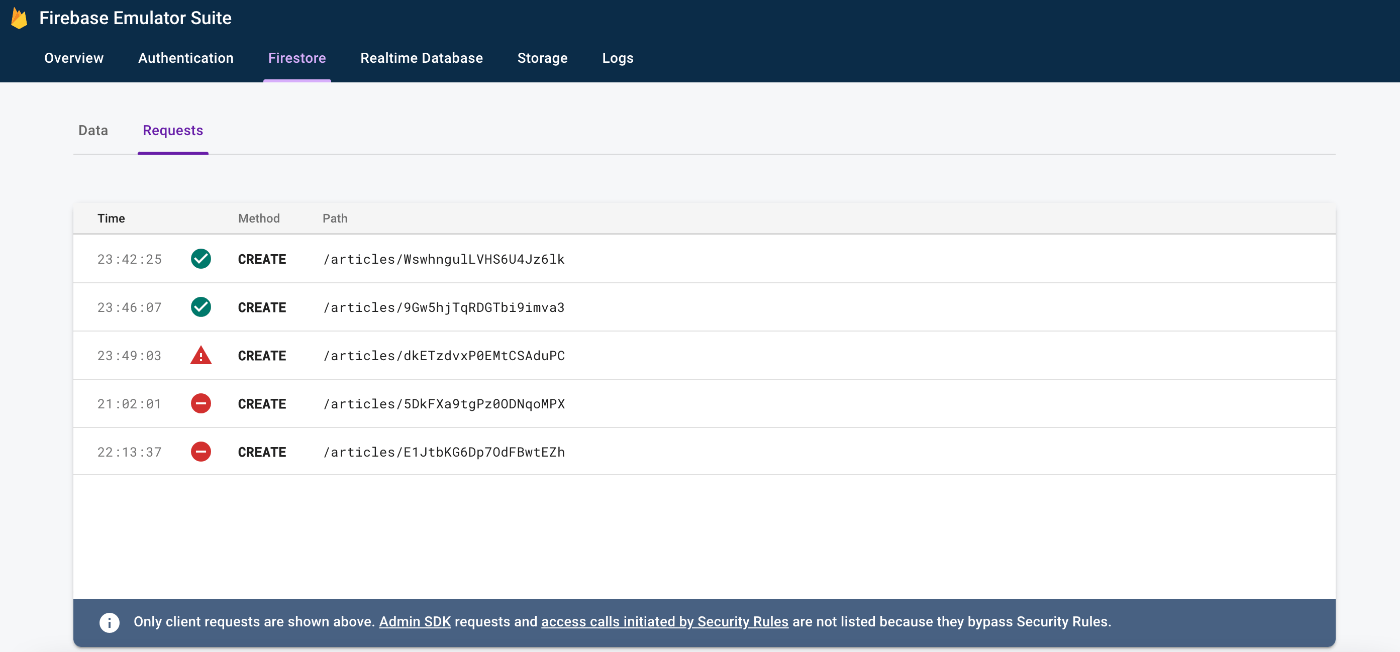
For each request logged, you could actually see the request & resource object & that can help you debug the rule.
Concluding thought - backend dev gonna be obsolete
I need to admit that after all this, I became a big fan of Firebase. Traditionally, every web/mobile application needed a backend because of this kind of complicated logic & gatekeeping which now can be done fairly easily at DB level itself.
I remember that during one of the interviews, I was asked the exact same question as to why do we still need backend when all backend does is CRUD operations & filtering. I did not have this visibility back then.
I was also chatting with a friend Nilesh Trivedi here in London. Both of us were entrepreneurs back in India, joined Meta the same day & left Meta at around the same time :). Nilesh once mentioned to me how the Database tech has evolved so much that all logic can pretty much stay in Frontend & communicate directly to the DB. I now understood what he meant back then.
As a backend web developer, this definitely worries me. The backend tech will not get completely obsolete as you still need them in a lot of async processing . My belief is backend tech will stay in fields like Machine Learning but from pure web development perspective, backend tech should ideally die in a few years.
Another reason for backend tech to die is - the evolution of web3. I am not sure when that gonna be mainstream though. With web3, you dont have one server to write/deploy your code to. The frontend ‘queries’ the network to get/write data to.
Going ahead, the web/mobile dev will be a Frontend only world :). With no backend, there are no server deployments, no fleet scaling/maintenance etc. You pretty much use the power of the user’s browser & the whole ‘backend scaling challenges’ disappear.
Special Thanks to ….
Greg, CTO Catapult, who did not stop me researching & implementing the RBAC & believing in me that things can stay efficient with Firebase & all Frontend implementation.
Geet, Arun Iyer & Souvik Das from Locus.sh with whom I happened to discuss the RBAC challenge & understood the earlier you have it in your system, the better it is.
Nilesh Trivedi who works as Transcend CTO for talking with me about the power of latest DB tech & instilling the seed in my mind about ‘it is Frontend dev’ world.